
資料庫的核心概念
Table 是資料庫中最基本的資料單位
每個 table 就像一張表格(像 Excel),包含許多「列(row)」與「欄(column)」。
每一列是一筆資料,每一欄是一個欄位(屬性)。
| id | name | |
|---|---|---|
| 1 | Alice | alice@example.com |
| 2 | Bob | bob@example.com |
這是 users 表格中的資料。
透過 Table 之間的關聯,建立有結構的資料關係
table 之間建立關聯(關聯欄位 + 外鍵),就能「把不同主題的資料串起來」。
這種結構化的設計叫做 關聯式資料庫模型(Relational Model)。
舉例:
users(使用者)
posts(文章)
我們不會把文章直接寫在 users 裡面,而是把 user_id 放到 posts 表裡,代表「這篇文章是誰寫的」。
如此一來:
資料是正規化的(不重複)
存取時可以用 JOIN 或 ORM 的 relationship 做關聯查詢,更直觀
建立關聯的好處
可以用以下直觀的方式,取出想要的資訊
1
2
writer = db.query(Writer).filter(Writer.id == 1).first()
print(writer.name, writer.profile.address)
or
1
2
# 一次查出 writer 和 profile(避免 lazy loading)
writer = db.query(Writer).join(Writer.profile).filter(Writer.id == 1).first()
把所有東西塞進一張表 ≠ 資料表設計
一筆「複雜」資料,會拆成多個 table
每個 table 專注處理一種資料型態
然後透過外鍵來表示它們之間的關係
常見的關聯類型
| 關係類型 | 說明 | ForeignKey | relationship |
|---|---|---|---|
| 一對一 (1:1) | 每個 user 對應一個 profile | Profile.user_id 並設 unique | uselist=False |
| 一對多 (1:N) | 一個 user 有多個 post | Post.author_id -> users.id | User.posts / Post.author |
| 多對一 (N:1) | 多個 post 對應一個 user | Post.author_id -> users.id | User.posts / Post.author |
| 多對多 (M:N) | 一篇文章有多個標籤,一個標籤對多篇文章 | 需要中介表(association table) | 兩邊都用 relationship(..., secondary=...) |
往下我們看範例來學習這四種關係吧 !
一對一關聯 (1:1)
先說明一下檔案結構會放些什麼內容
api -> 主要放 router 類的 codes
crud -> 就是對 db 的 CRUD
db -> 與 db 建立連線的邏輯
models -> table 的資料結構
schemas -> pydantic 的資料結構
這邊主要介紹 models 下的 codes, 畢竟 table 之間的關聯就是透過 models 下的邏輯去連結的。 其他的部分只是週邊,目的是讓前端可以做 CRUD 而已。
我們主要會建立 writer 和 profile
主表 models/writer_models.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
from db.database import Base
class Writer(Base): # 繼承自 SQLAlchemy 的 Base,代表這是一個資料表模型
__tablename__ = "writers" # 資料表的名稱會是 writers
id = Column(Integer, primary_key=True, index=True)
# 主鍵(Primary Key),自動遞增的整數,唯一識別每個 writer
# index=True:建立索引,提高查詢效率
name = Column(String)
# 作者名稱,儲存為文字欄位,沒有設 unique,代表可以重複
email = Column(String, unique=True)
# 作者的 email 欄位
# unique=True:要求每個 email 必須唯一,不可重複(避免重複註冊)
profile = relationship("Profile", back_populates="writer", uselist=False)
# 定義與 Profile 模型的一對一關聯
# "Profile":指向另一個模型的名稱
# back_populates="writer":Profile 端也會有 writer 欄位,雙向連結
# uselist=False:表示這是一對一,而不是一對多(否則會變成 list)
從表 models/profile_models.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
from db.database import Base
class Profile(Base): # 繼承 Base,這也是一個資料表模型
__tablename__ = "profiles" # 對應到資料表名稱為 profiles
id = Column(Integer, primary_key=True)
# 主鍵,同樣是自動遞增的整數
age = Column(Integer)
# 年齡欄位,整數型別
bio = Column(String)
# 自我介紹欄位(簡短文字敘述)
writer_id = Column(Integer, ForeignKey("writers.id"), unique=True)
# 外鍵:關聯到 writers 資料表的 id 欄位
# ForeignKey("writers.id"):表示這欄是關聯的欄位
# unique=True:限制每個 profile 只能對應一個 writer,實現一對一關聯
writer = relationship("Writer", back_populates="profile")
# 與 Writer 模型建立雙向連結
# back_populates="profile":與 Writer 的 profile 欄位對應
# 讓你可以透過 `profile.writer` 取得對應的 writer 資料
判斷主表與從表的依據
| 判斷依據 | 說明 |
|---|---|
| 誰是主要實體(核心資料)? | 主表通常是「主角」,是其他資料的核心。例如:使用者、商品、文章。 |
| 誰依賴誰存在? | 從表的存在依賴主表。例如,一個 Profile 一定要有對應的 Writer 才成立。 |
| 誰擁有外鍵? | 從表通常會有 ForeignKey 欄位,指向主表的主鍵。 |
| 資料更新順序的依賴性? | 通常會先新增主表,再新增從表,因為從表要依賴主表的 id。 |
執行
我們直接由對應的 openapi 去操作
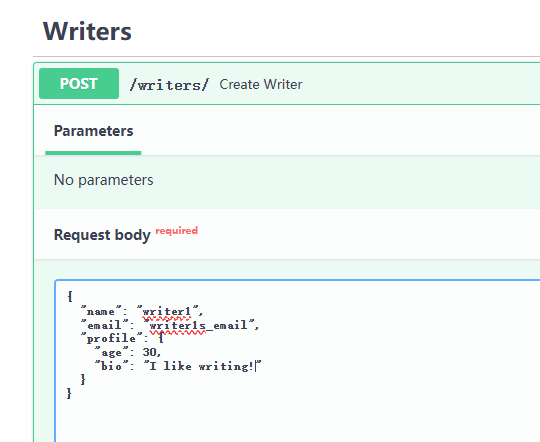
我們先 Create 一個 writer 的資料吧
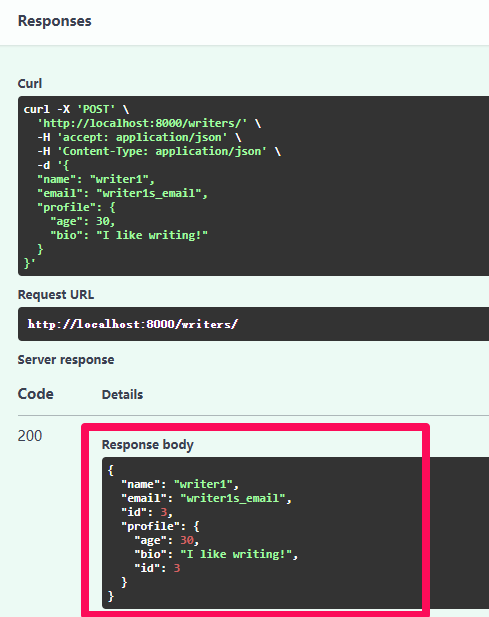
查詢剛剛建立的 writer
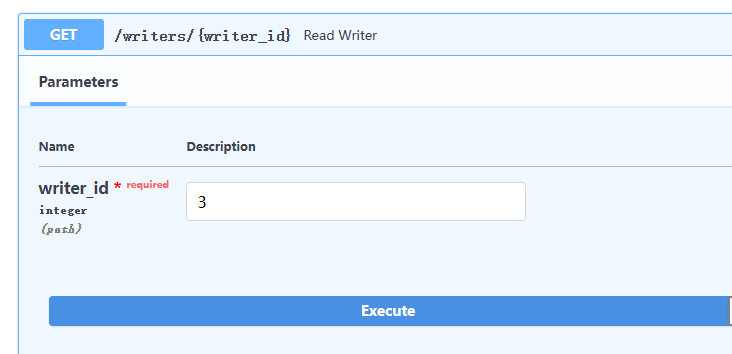
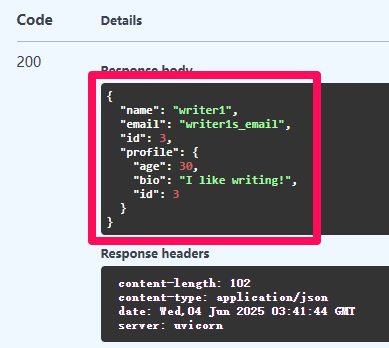
使用 profile 去查
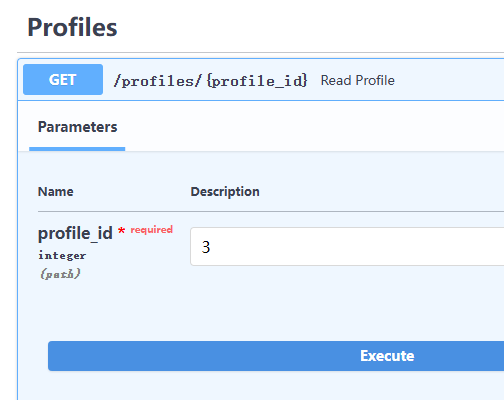
也可得到該 profile 對應的 writer
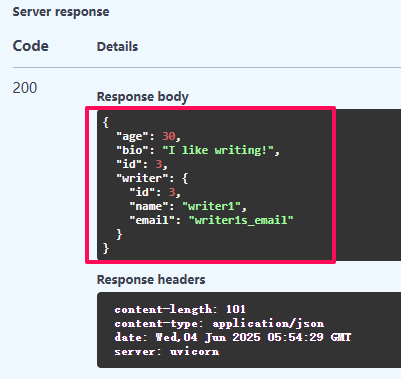
再試試看吧!