
讀 Excel 的 python lib
Excel 是大家常常拿來整理資料的工具,它非常的方便好用,這邊就不需贅述了。 但如何讀取 Excel 的資料去做更複雜的資料整理?
openpyxl 和 pandas 都可以,以下針對做兩個模組的比較。
openpyxl vs pandas
| 功能 | Openpyxl | Pandas |
|---|---|---|
| 讀取速度 | 較慢 | 較快 |
| 寫入速度 | 較慢 | 較快 |
| 格式支援 | 完整 | 有限 |
| 數據處理 | 基本的讀寫操作 | 強大的數據分析和處理功能 |
| 圖表 | 支援 | 不支援 |
| 公式 | 支援 | 不支援 |
| 單元格格式 | 精細控制 | 基本支援 |
| 多工作表處理 | 支援 | 支援 |
Openpyxl 的優點:
- 完全支援 Excel 功能:Openpyxl 支援 Excel 的大部分功能,包括讀取和寫入格式、圖表、公式等。
- 細節控制:可以更精細地控制單元格的格式、樣式和資料驗證。
- size 小: openpyxl 大約 10 MB; pandas 依賴性多(像是 numpy), 大約 100 MB.
考慮到寫完的工具,要導出執行檔給別人使用,因此選擇使用 openpyxl,這樣執行檔的 size 可以大幅下降。
openpyxl 功能介紹
Openpyxl 是一個用於讀取和寫入 Excel 檔案的 Python 庫。它支援 Excel 2010 xlsx/xlsm/xltx/xltm 檔案格式。以下是 openpyxl 的一些主要功能和使用方法介紹:
- 讀取 Excel 檔案:可以從現有的 Excel 檔案中讀取數據。
- 寫入 Excel 檔案:可以創建新的 Excel 檔案並寫入數據。
- 修改 Excel 檔案:可以在現有的 Excel 檔案中添加、刪除或修改數據。
- 格式化:支援單元格的格式化,例如字體、顏色、邊框等。
- 圖表:可以在 Excel 中創建各種圖表。
- 公式:支援讀取和寫入 Excel 公式。
- 資料驗證:可以設定單元格的資料驗證規則。
示範讀檔
現在有個 basketball.xlsx 紀錄 NBA 23/24 賽季平均的排行榜,我要使用 openpyxl 將資料輸出
得分 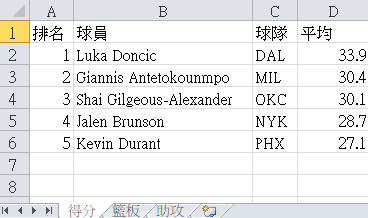
籃板 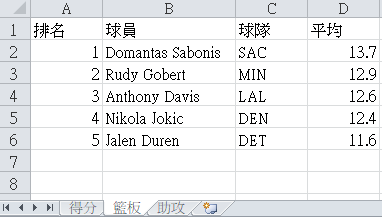
助攻 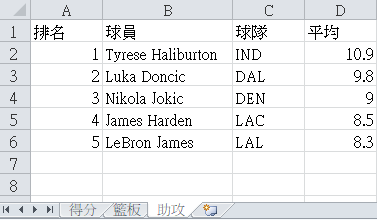
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from openpyxl import load_workbook
# Read Excel file
wb = load_workbook('basketball.xlsx')
print("sheets name : ")
sheet_name = wb.sheetnames # get all sheetnames
for name in sheet_name:
print(name)
print()
ws = wb['得分'] # assign worksheet by sheetname
for row in ws.iter_rows(values_only=True):
print(row)
print("----------")
ws = wb['籃板']
for row in ws.iter_rows(values_only=True):
print(row)
print("----------")
ws = wb['助攻']
for row in ws.iter_rows(values_only=True):
print(row)
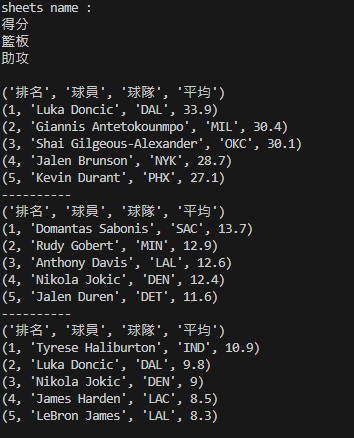
程式碼很簡單吧 ! 解釋都在註解中
示範寫檔
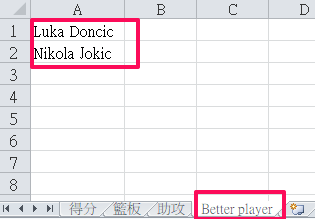
現在我們想要在這些球員中找出更出色的球員,也就是那些球員同時出現在得分、籃板、助攻的排行榜上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from openpyxl import load_workbook
import numpy as np
# Read Excel file
wb = load_workbook('basketball.xlsx')
temp = []
sheet_name = wb.sheetnames
for name in sheet_name:
ws = wb[name]
# min_row=2 從第 2 個 row 開始讀取, 因為第一個 row 是 header
for row in ws.iter_rows(min_row=2,values_only=True):
temp.append(row[1])
names = np.array(temp)
unique_values, counts = np.unique(names, return_counts=True)
# 找出出現次數大於 1 的值
duplicates = unique_values[counts > 1]
# 添加新工作表
ws2 = wb.create_sheet(title="Better player")
# 在新工作表中寫入數據
ws2['A1'] = duplicates[0]
ws2['A2'] = duplicates[1]
# 儲存檔案
wb.save("basketball.xlsx")
以上!