
Python Libraries for Reading Excel
Excel is a commonly used tool for organizing data due to its convenience and versatility. But how can we read Excel data for more complex data processing?
openpyxl and pandas are two popular options, and here is a comparison of the two modules.
openpyxl vs pandas
| Feature | Openpyxl | Pandas |
|---|---|---|
| Read Speed | Slower | Faster |
| Write Speed | Slower | Faster |
| Format Support | Complete | Limited |
| Data Processing | Basic r/w operations | Powerful data analysis and processing capabilities |
| Charts | Supported | Not Supported |
| Formulas | Supported | Not Supported |
| Cell Formatting | Fine control | Basic support |
| Multi-Sheet Handling | Supported | Supported |
Advantages of Openpyxl:
- Full Support for Excel Features: Openpyxl supports most Excel features, including reading and writing formats, charts, formulas, etc.
- Detailed Control: Provides finer control over cell formatting, styles, and data validation.
- Smaller Size: Openpyxl is around 10 MB; pandas has many dependencies (such as
numpy) and is around 100 MB.
Considering that the completed tool needs to be packaged as an executable for others to use, using openpyxl will significantly reduce the size of the executable.
Introduction to Openpyxl Features
Openpyxl is a Python library for reading and writing Excel files. It supports the Excel 2010 xlsx/xlsm/xltx/xltm file formats. Here are some of the main features and usage methods of openpyxl:
- Reading Excel Files: Allows reading data from existing Excel files.
- Writing Excel Files: Enables creating new Excel files and writing data to them.
- Modifying Excel Files: Allows adding, deleting, or modifying data in existing Excel files.
- Formatting: Supports formatting cells, such as fonts, colors, borders, etc.
- Charts: Can create various charts in Excel.
- Formulas: Supports reading and writing Excel formulas.
- Data Validation: Allows setting data validation rules for cells.
Example: Reading a File
There is a file named basketball.xlsx that records the average rankings of the NBA 23/24 season. I will use openpyxl to output the data.
Scoring 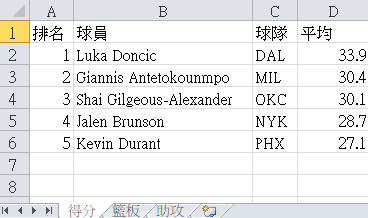
Rebounds 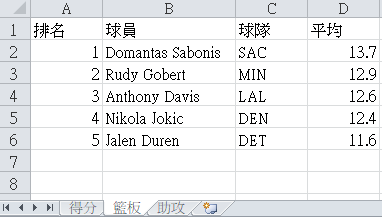
Assists 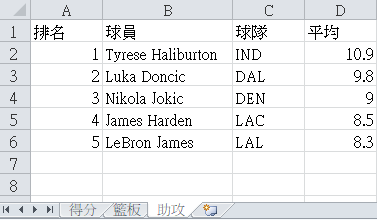
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
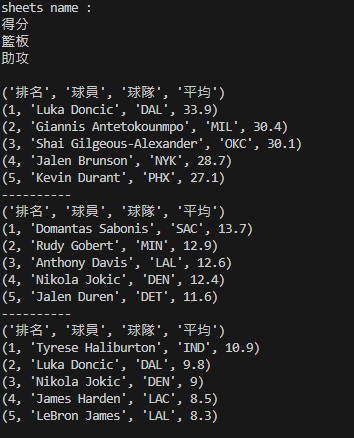
from openpyxl import load_workbook
# Read Excel file
wb = load_workbook('basketball.xlsx')
print("sheets name : ")
sheet_name = wb.sheetnames # get all sheetnames
for name in sheet_name:
print(name)
print()
ws = wb['得分'] # assign worksheet by sheetname
for row in ws.iter_rows(values_only=True):
print(row)
print("----------")
ws = wb['籃板']
for row in ws.iter_rows(values_only=True):
print(row)
print("----------")
ws = wb['助攻']
for row in ws.iter_rows(values_only=True):
print(row)
Sure, here’s the explanation of the code with comments included for clarity
Example: Writing to a File
We want to identify outstanding players who appear in the rankings for scoring, rebounds, and assists.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from openpyxl import load_workbook
import numpy as np
# Read Excel file
wb = load_workbook('basketball.xlsx')
temp = []
sheet_name = wb.sheetnames
for name in sheet_name:
ws = wb[name]
# Iterate over rows starting from the 2nd row (skipping the header)
for row in ws.iter_rows(min_row=2,values_only=True):
temp.append(row[1])
names = np.array(temp)
unique_values, counts = np.unique(names, return_counts=True)
# Find unique names and their counts
duplicates = unique_values[counts > 1]
# Add a new worksheet
ws2 = wb.create_sheet(title="Better player")
# Write the duplicated player names to the new worksheet
ws2['A1'] = duplicates[0]
ws2['A2'] = duplicates[1]
# Save the file
wb.save("basketball.xlsx")
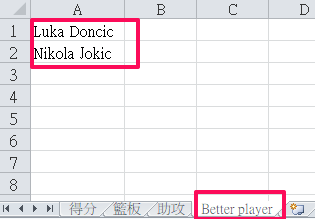
That’s all.